Ноль нулю не равен!
Разумеется, математика оперирует исключительно абстрактными понятиями. Самым ярким примером таких абстракций могут служить числа. Возьмём, к примеру, число 2. Абстрактному понятию «два» можно поставить в соответствие и 2 рубля, и 2 килокалории, и 2 яблока, и 2 щелчка мышью, и 2 кванта света, и даже 2 Вселенные.
Среди математических абстракций есть и более отвлечённые понятия, как-то: точка, прямая, бесконечность, ноль. Появившись позже других математических абстракций, ноль до сих пор остаётся самой большой загадкой. С одной стороны, ноль рассматривается в математике как число, поскольку он участвует в математических операциях наряду с остальными числами. С другой стороны, ноль обладает свойствами, не свойственными числам: в частности, он не может выступать в роли делителя (см. рисунок).
В связи с вышесказанным, предлагается чётко разграничить два разных математических понятия: «ноль» и «нуль», которые в настоящее время повсеместно употребляются как синонимы [1].
1. ЧТО ТАКОЕ «НОЛЬ»?
Чтобы определиться с понятием «ноля», вычленим класс математических задач, связанных с его появлением и применением.
1.1. Возникновение «ноля»
Единственным источником, или причиной появления «ноля» является задача вычитания числа из самого себя, либо её эквивалент, связанный с использованием так называемых отрицательных чисел, например:
• х-х=0;
• х+(-х)=0.
При этом важно иметь в виду, что объекты реального мира, сопоставленные с абстрактным понятием «ноля», никуда не исчезают, они остаются во Вселенной!
Например, если у вас было 2 рубля, и вы заплатили 2 рубля, то эти деньги просто перешли к другому владельцу. Даже если вы сожгли бумажные деньги, то они как физический объект не исчезли, а изменили своё состояние, превратившись в пепел и в энергию. И в первом, и во втором примере «ноль» будет означать отсутствие денег лично у вас, но не их исчезновение из Вселенной.
1.2. Применение «ноля»
Во-первых, «ноль» применяется в различных математических операциях, как-то:
• 0 + 0 = 0;
• 0 — 0 = 0;
• 0 + x = x;
• 0 — x = -x;
• 0 — (-x) = х;
• 0 · x = 0;
• 0 / x = 0;
• 0 · 0 = 0;
• 0^x = 0;
• x^0 = 1;
• 0! = 1;
• sqrt(0) = 0.
Во-вторых, «ноль» применяется для указания пустого разряда в позиционных системах счисления, например:
• 101 – в десятичном числе «сто один» 0 обозначает отсутствие разряда десятков;
• 1010 – в двоичном числе «десять» левый 0 обозначает отсутствие разряда с весом 4.
Характерно, что во всех приведенных примерах символ «0» используется в качестве цифры. Поэтому предлагается в задачах такого рода для обозначения цифры «0» употреблять термин «ноль», то есть слово с буквой «о», так как она своим внешним видом напоминает цифру «0». В английском варианте это может быть слово “zero”.
2. ЧТО ЖЕ ТАКОЕ «НУЛЬ»?
Определим теперь класс задач, где тот же самый термин выступает совершенно в другой роли, в связи с чем, требует для своего обозначения принципиально иного слова:
• прежде всего, отнесём сюда задачи, в которых «нуль» обозначает предел убывающей числовой последовательности, например, задачу последовательного деления отрезка или числа;
• сюда же следует отнести и задачу деления произвольного числа на «нуль»;
• и, наконец, использование «нуля» для обозначения размера математической точки.
Фактически, все эти задачи сводятся к одной, причём термину «нуль» здесь соответствует уже ни цифра, ни число, а совершенно иное понятие, синонимом которого может служить термин «НИЧТО», то есть полное отсутствие нечто. В этих задачах НЕЧТО последовательно уменьшается до своего бесследного исчезновения из Вселенной!
Именно по этой причине здесь будет уместен термин «нуль», созвучный с итал. nulla «ничто»; лат. nullus «никакой, ни один, несуществующий, пустой»; нем. null «нуль, недействительный, мизер»; англ. null «незначительный, несущественный, несуществующий, пустой».
3. СУЩЕСТВУЕТ ЛИ «НУЛЬ»?
Следует особо отметить, что просто различать термины «ноль» и «нуль» недостаточно.
Надо понимать, что термин «нуль»:
• не является цифрой;
• не является числом;
• не является синонимом термина «ноль»;
• не имеет никаких аналогов во Вселенной и, следовательно, не имеет графического образа;
• не реализуем практически, а математическое применение «нуля» является грубейшим упрощением действительности.
Так, использование «нУля» в математике можно сравнить с применением ТОПОРА для раскалывания атомных ядер в физике.
Самым главным следствием отождествления термина «нУль» с понятием «ничто» является пребывание математики (а с ней и всей науки!) в рамках самой примитивной трёхмерной модели Мироздания и принципиальная невозможность перехода к математическому описанию Высших миров многомерной Вселенной.
1. Микиша А. М., Орлов В. Б. Толковый математический словарь: Основные термины. М.: Рус. яз., 1989. – 244 с.
18 марта 2012 года
Как это в природе не существует?!
А это:
"Из ничего и выйдет ничего"
"Из ничего не выйдет ничего"
Оба высказывания верны и даже претендуют на гениальность.:)
"Ничего с плюсом" = "ничего с минусом"
А когда у нас плюс равен минусу?
только тогда , когда их "подопечных"(чисел) и вовсе нет!
Уф! ну как? :))
PS
Переоценить значение null и в математике, и в алгоритмике..ну
в программировании невозможно- на нем все теории держатся.
Так не все ли равно с "у" или с "о":)))
И как это я у вас пропустила ?!
Ира, спасибо большое за отклик!
Понятие «ничего» в обиходе весьма расплывчато, зато в математике оно – конкретнее некуда: полное отчутствие чего-либо, да ещё с претензией на обладание свойством быть при этом чем угодно – хоть целой Вселенной. Так что, математика мне представляется существенно «генеальнее». 🙂 Но Ваши +null и -null мне очень понравились! В программировании же null ничего интересного из себя, на мой взгляд, не представляет – обычная условность.
Но если говорить о нУле серьёзно, то наделение его ничтожно малой величиной (ЗНАЧИТЕЛЬНО меньшей, чем допустимая погрешность вычислений) позволит решить сразу несколько наиважнейших задач:
1) математика перестанет быть разделом научной фантастики;
2) люди смогут, НАКОНЕЦ-ТО, делить на нУль;
3) будет положен конец атеизму в науке, и люди увидят, ГДЕ же находится БОГ, то есть Божественный Мир!
А как же всех переучить?
Мир не перевернется вверх дном?:))
Да, в программировании null-pointer-
адрес в котором ничего нет ,вещь весьма,кстати, полезная-
условность, . но приятная :)))
Мир обязательно перевернётся, и очень скоро, но не ввех дном. 🙂
Тогда и прозреют все.
Ира, обратите внимание на цифры под моим «пророчеством»: 08.08. и 2012 2012.
Как-то не по себе становится от таких совпадений. при отсутствии случайностей.
Есть очень хорошее средство — делай снами, делай, как мы, делай лучше нас:
сначала сплюнуть через левое плечо-тьфу,тьфу,тьфу,
потом трижды постучать по дереву(я обычно стучу по своей голове),
а потом перевернуться на одной ножке.
И все.И никаких пророчеств :)))
Сразу видно, что совет исходит от прекрасной половины человечества:
ножки, ручки, глазки. А где их взять, когда в наличии только ноГи.
Не могу, к сожалению, передать звук Г в слове ноГи. :)))
Это тоже просто :
ноhи ? Это имелось в виду?
( "h" — отсутствующий звук русского языка):))
Спасибо! Тогда, может быть, точнее будет так: hg?
Хотя звук украинский, а там таких букв нет. 🙂
Что такое принцип ноль не ноль

Именно в нуле любят собираться ошибки. На сайте вроде просто поле, а где-то внутри система делит на него при подсчете процента покупки. Подставил ноль — все сломалось. Профит! Баг! Или продуман только позитивный сценарий — всегда заказывают больше нуля книг / пицц / настолок. Ввел ноль, а код обработки значения не написан. Опять сломалось… Или оставил поле пустым, а система тебе БАЦ, и эксепшен…
Поле ввода — цифры есть
Тут все просто. Если видим числовое поле, пробуем ноль
Число книг: ноль / не ноль.
Кол-во пар обуви: ноль / не ноль.
Возраст пациента: ноль / не ноль.
Номер заказа: ноль / не ноль.
Выручка в рублях: ноль / не ноль.
Коэффициент похожести: ноль / не ноль.
Это логично, такую проверку делают многие. Легко найти число в числовом поле!
Но что, если поле не числовое? Сразу затык.
Длина строки
Конечно, можно! Кладем наше поле на числовую ось и получаем класс «длина строки». Та-а-а-ак, допустимое имя по ТЗ — от 3 до 6 символов. Окей, а как насчет нуля? Что будет, если оставить строку пустой? Так мы применяем класс «ноль-не ноль».
Длина имени: ноль / не ноль.
Длина эл почты: ноль / не ноль.
Длина пароля: ноль / не ноль.
Длина названия организации: ноль / не ноль.
Состояние объекта — цифр нет
Легко подставить ноль туда, где есть цифры. Несложно положить символьную строку на числовую ось и найти границы по длине строки. Что будет, если оставить строку пустой? А если заполнить? А если ввести только один символ (пограничное значение)?
Число книг: ноль / не ноль.
Символов в имени: ноль / не ноль.
Сложно применить класс «ноль / не ноль» там, где вроде бы нет цифр. И даже длины строки нет. В итоге тестировщик Вася ловит баг, но не может потом воспроизвести. Потому что не локализовал, не нашел точное условие → не записал его в шаги → задачу отложили → спустя месяц по шагам автора уже не воспроизводится, потому что его учетку удалили. А проблема была в ней, ведь Вася оплачивал продукты по PayPal до того, как возможность прикрыли. И забыли отмигрировать данные. На новой учетке даже возможности оплатить по PayPal нету (ноль) → баг не воспроизведется, ведь нам нужна учетка, где количество оплат по PayPal «не ноль».
И сидят Вася с Петей-разработчиком, копаются в логах, пытаются понять, как воспроизвести проблему. Или еще хуже — пожимают плечами, «А! Видимо, само починилось в рамках другой задачи» и закрывают баг как Cannot reproduce. И душа спокойна — теперь то работает! До тех пор, пока у реального пользователя баг не выстрелит. И тогда начнется паника, БЛОКЕР-приоритеты и все такое. А потом Петя поймет, в чем дело было, да даст Васе подзатыльник — сразу надо было про «ноль-не ноль» думать!
Учитесь видеть «ноль-не ноль» не только в числах и длине строк, но и в состояниях объекта:
Пользователь авторизован / не авторизован.
Заходил на сайт ранее / не заходил.
Заполнял профиль / не заполнял.
Аватарку загружал / не грузил.
Деньги снимал / не снимал.
Это самые крутые примеры класса, потому что о них не задумываются. Их пропускают. И именно поэтому их надо проверять. Как при поиске багов, так и при локализации конкретной ошибки: «Так-с, упало. А это всегда так или только при первом просмотре (раньше не смотрел — ноль, уже видел — не ноль)?».
Ноль на выходе
Не забывайте — ноль может быть не только на входе, но и на выходе!
— Ввести ноль в числовое поле,
— Оставить строку символов пустой.
— После совершения покупки баланс уйдет в ноль.
— После обработки поле станет пустым.
— Поиск вернет ноль результатов (хотя на входе у нас непустая строка поиска).
— Отчет на указанную дату будет пустым (опять же, дата на входе была указана не-ноль).
Пример
Посмотрим на примере Дадаты. Там куча нестандартных мест для проверки нашего класса «ноль-не ноль».
При регистрации у нас три унылых символьных поля, там все просто — поле заполнено или нет. Давайте найдем все классы с нулем для обработки файлов!
После авторизации появляется форма загрузки — https://dadata.ru/clean/.
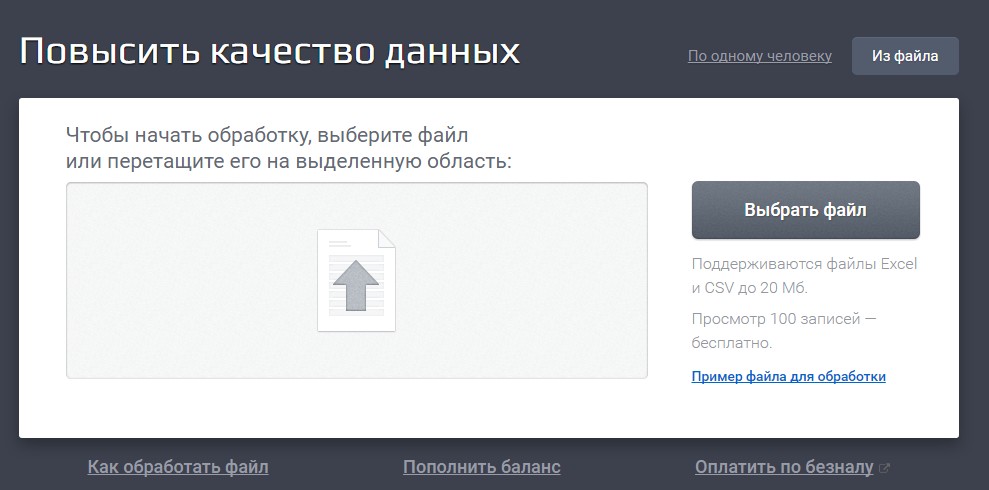
Выбираем файл — Дадата отображает структуру. Если она вдруг неправильно определила тип, его всегда можно изменить в выпадающем списке:
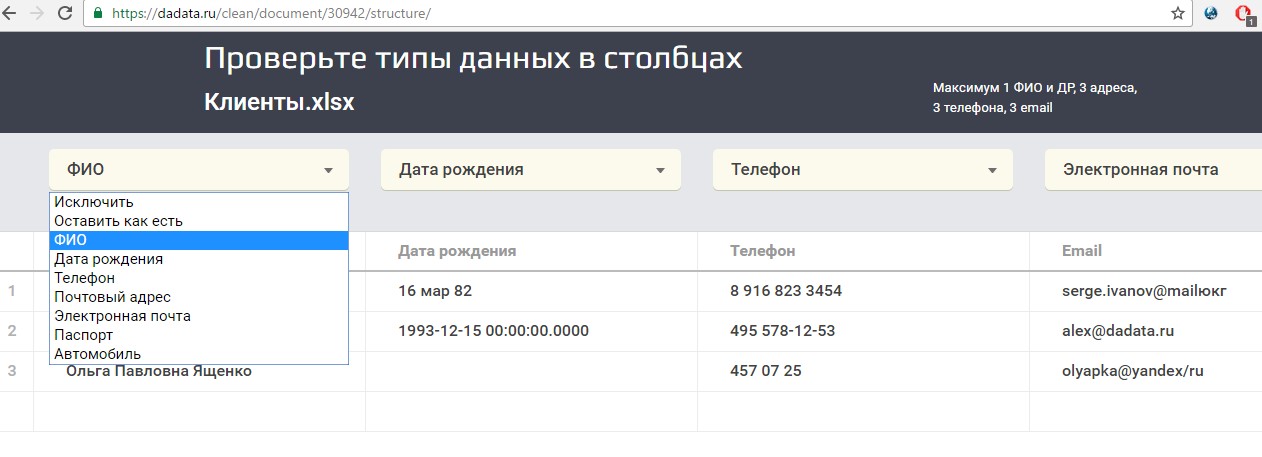
Проверив структуру, переходим к предварительному результату. Если все ок, оплачиваем и получаем итоговый файл.
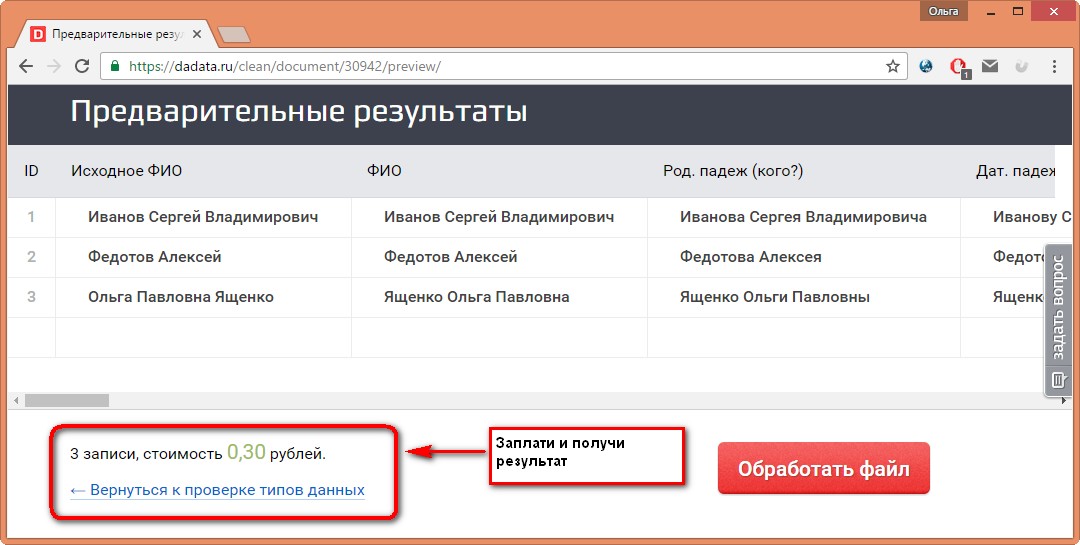
— Файл может быть пустой: ноль строк, ноль колонок. Ок.
— Система распознает первую строку как шапку. А что, если у нас будет ноль «значимых» строк?
— Мы платим за обработку — а что, если у нас ноль рублей на счету? А что, если после обработки у нас станет ноль или даже меньше? Помним о том, что ноль может быть не только на входе, но и на выходе.
— А что, если у нас на выходе будет ноль данных? Если мы под видом ФИО пришлем фигню из серии “12345”? Да, колонки будут, но пустые же!
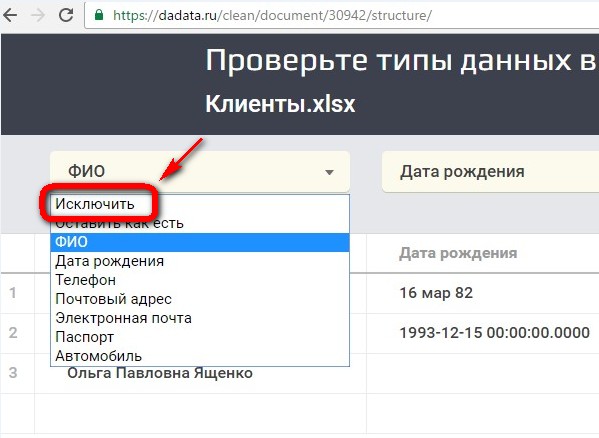
— А что, если на выходе вообще ничего? Присмотритесь к структуре, там же есть кнопка «Исключить столбец»! А что, если мы исключим все столбцы и получим на выходе ноль?
Проверьте себя, найдите все нули в:
— форме обработки по одному человеку;
Чур, спойлеры в комментах не писать! =)
Просто в следующий раз, тестируя свою систему, вспомните о том, что ноль есть не только в числах и длинах полей. Ищите его там, где другие не ищут!Другие примеры:
— Период сегодня-вчера, если он длится 0 дней
— Применение класса «ноль-не ноль» при подключении к JMS
— Как пустой JSON вешает библиотечку Axis
Ноль нулю не равен!
Разумеется, математика оперирует исключительно абстрактными понятиями. Самым ярким примером таких абстракций могут служить числа. Возьмём, к примеру, число 2. Абстрактному понятию «два» можно поставить в соответствие и 2 рубля, и 2 килокалории, и 2 яблока, и 2 щелчка мышью, и 2 кванта света, и даже 2 Вселенные.
Среди математических абстракций есть и более отвлечённые понятия, как-то: точка, прямая, бесконечность, ноль. Появившись позже других математических абстракций, ноль до сих пор остаётся самой большой загадкой. С одной стороны, ноль рассматривается в математике как число, поскольку он участвует в математических операциях наряду с остальными числами. С другой стороны, ноль обладает свойствами, не свойственными числам: в частности, он не может выступать в роли делителя (см. рисунок).
В связи с вышесказанным, предлагается чётко разграничить два разных математических понятия: «ноль» и «нуль», которые в настоящее время повсеместно употребляются как синонимы [1].
Чтобы определиться с понятием «ноля», вычленим класс математических задач, связанных с его появлением и применением.
1.1. Возникновение «ноля»
Единственным источником, или причиной появления «ноля» является задача вычитания числа из самого себя, либо её эквивалент, связанный с использованием так называемых отрицательных чисел, например:
• х-х=0;
• х+(-х)=0.
При этом важно иметь в виду, что объекты реального мира, сопоставленные с абстрактным понятием «ноля», никуда не исчезают, они остаются во Вселенной!
Например, если у вас было 2 рубля, и вы заплатили 2 рубля, то эти деньги просто перешли к другому владельцу. Даже если вы сожгли бумажные деньги, то они как физический объект не исчезли, а изменили своё состояние, превратившись в пепел и в энергию. И в первом, и во втором примере «ноль» будет означать отсутствие денег лично у вас, но не их исчезновение из Вселенной.
Во-первых, «ноль» применяется в различных математических операциях, как-то:
• 0 + 0 = 0;
• 0 — 0 = 0;
• 0 + x = x;
• 0 — x = -x;
• 0 — (-x) = х;
• 0 · x = 0;
• 0 / x = 0;
• 0 · 0 = 0;
• 0^x = 0;
• x^0 = 1;
• 0! = 1;
• sqrt(0) = 0.
Во-вторых, «ноль» применяется для указания пустого разряда в позиционных системах счисления, например:
• 101 – в десятичном числе «сто один» 0 обозначает отсутствие разряда десятков;
• 1010 – в двоичном числе «десять» левый 0 обозначает отсутствие разряда с весом 4.
Характерно, что во всех приведенных примерах символ «0» используется в качестве цифры. Поэтому предлагается в задачах такого рода для обозначения цифры «0» употреблять термин «ноль», то есть слово с буквой «о», так как она своим внешним видом напоминает цифру «0». В английском варианте это может быть слово “zero”.
2. ЧТО ЖЕ ТАКОЕ «НУЛЬ»?
Определим теперь класс задач, где тот же самый термин выступает совершенно в другой роли, в связи с чем, требует для своего обозначения принципиально иного слова:
• прежде всего, отнесём сюда задачи, в которых «нуль» обозначает предел убывающей числовой последовательности, например, задачу последовательного деления отрезка или числа;
• сюда же следует отнести и задачу деления произвольного числа на «нуль»;
• и, наконец, использование «нуля» для обозначения размера математической точки.
Фактически, все эти задачи сводятся к одной, причём термину «нуль» здесь соответствует уже ни цифра, ни число, а совершенно иное понятие, синонимом которого может служить термин «НИЧТО», то есть полное отсутствие нечто. В этих задачах НЕЧТО последовательно уменьшается до своего бесследного исчезновения из Вселенной!
Именно по этой причине здесь будет уместен термин «нуль», созвучный с итал. nulla «ничто»; лат. nullus «никакой, ни один, несуществующий, пустой»; нем. null «нуль, недействительный, мизер»; англ. null «незначительный, несущественный, несуществующий, пустой».
3. СУЩЕСТВУЕТ ЛИ «НУЛЬ»?
Следует особо отметить, что просто различать термины «ноль» и «нуль» недостаточно.
Надо понимать, что термин «нуль»:
• не является цифрой;
• не является числом;
• не является синонимом термина «ноль»;
• не имеет никаких аналогов во Вселенной и, следовательно, не имеет графического образа;
• не реализуем практически, а математическое применение «нуля» является грубейшим упрощением действительности.
Так, использование «нУля» в математике можно сравнить с применением ТОПОРА для раскалывания атомных ядер в физике.
Самым главным следствием отождествления термина «нУль» с понятием «ничто» является пребывание математики (а с ней и всей науки!) в рамках самой примитивной трёхмерной модели Мироздания и принципиальная невозможность перехода к математическому описанию Высших миров многомерной Вселенной.
1. Микиша А. М., Орлов В. Б. Толковый математический словарь: Основные термины. М.: Рус. яз., 1989. – 244 с.
18 марта 2012 года
Как это в природе не существует?!
А это:
"Из ничего и выйдет ничего"
"Из ничего не выйдет ничего"
Оба высказывания верны и даже претендуют на гениальность.:)
"Ничего с плюсом" = "ничего с минусом"
А когда у нас плюс равен минусу?
только тогда , когда их "подопечных"(чисел) и вовсе нет!
Уф! ну как? :))
PS
Переоценить значение null и в математике, и в алгоритмике..ну
в программировании невозможно- на нем все теории держатся.
Так не все ли равно с "у" или с "о":)))
И как это я у вас пропустила ?!
Ира, спасибо большое за отклик!
Понятие «ничего» в обиходе весьма расплывчато, зато в математике оно – конкретнее некуда: полное отчутствие чего-либо, да ещё с претензией на обладание свойством быть при этом чем угодно – хоть целой Вселенной. Так что, математика мне представляется существенно «генеальнее». �� Но Ваши +null и -null мне очень понравились! В программировании же null ничего интересного из себя, на мой взгляд, не представляет – обычная условность.
Но если говорить о нУле серьёзно, то наделение его ничтожно малой величиной (ЗНАЧИТЕЛЬНО меньшей, чем допустимая погрешность вычислений) позволит решить сразу несколько наиважнейших задач:
1) математика перестанет быть разделом научной фантастики;
2) люди смогут, НАКОНЕЦ-ТО, делить на нУль;
3) будет положен конец атеизму в науке, и люди увидят, ГДЕ же находится БОГ, то есть Божественный Мир!
А как же всех переучить?
Мир не перевернется вверх дном?:))
Да, в программировании null-pointer-
адрес в котором ничего нет ,вещь весьма,кстати, полезная-
условность, . но приятная :)))
Мир обязательно перевернётся, и очень скоро, но не ввех дном. ��
Тогда и прозреют все.
Ира, обратите внимание на цифры под моим «пророчеством»: 08.08. и 2012 2012.
Как-то не по себе становится от таких совпадений. при отсутствии случайностей.
Есть очень хорошее средство — делай снами, делай, как мы, делай лучше нас:
сначала сплюнуть через левое плечо-тьфу,тьфу,тьфу,
потом трижды постучать по дереву(я обычно стучу по своей голове),
а потом перевернуться на одной ножке.
И все.И никаких пророчеств :)))
Сразу видно, что совет исходит от прекрасной половины человечества:
ножки, ручки, глазки. А где их взять, когда в наличии только ноГи.
Не могу, к сожалению, передать звук Г в слове ноГи. :)))
Это тоже просто :
ноhи ? Это имелось в виду?
( "h" — отсутствующий звук русского языка):))
Спасибо! Тогда, может быть, точнее будет так: hg?
Хотя звук украинский, а там таких букв нет. ��
Что такое принцип ноль не ноль



- Портал
- Форум
- Тренинги

Что пишут в блогах
- JIRA: как найти задачу, где когда-то был исполнителем
- Оффер через месяц после курса! Интервью с выпускницей ПОИНТ
- Таблица принятия решений — decision table (таблица решений)
- Как понять, что именно нужно автоматизировать на проекте? Закулисье тест-менеджерства
- Тестирование юзабилити: как и чем оно спасает бизнес
- Числовая оценка работы тестировщиков
- Где взять опыт автоматизации без опыта и трудоустройства
- Семь бесплатных уроков по тестированию ПО для вас!
- Виды, типы, подходы, уровни, методы, стратегии тестирования
- Ключевые принципы адаптации новичка в коллективе: секреты успеха

Что пишут в блогах (EN)
- Recruit And interview people. Do not just fill roles
- Testing The Triangle Application
- On Modelling
- June 2023 EvilTester.com and Patreon Content Summary
- The Abstract Battle for Irrelevancy
- Five for Friday – July 7, 2023
- AI Testing – Measures and Scores, Part 2
- Don’t Build a Pseudo-Number Generator
- AI Muggins
- AI Testing – Measures and Scores, Part 1
Разделы портала
Онлайн-тренинги
| Классы эквивалентности для строки, которая обозначает число |
| 02.02.2011 18:28 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Ещё в самом начале предыдущего онлайн-тренинга «Практикум по тест-дизайну» я обещал ученикам написать о том, как выполнять разбиение входных данных на подобласти (классы эквивалетности) в ситуациях, когда в поле ввода можно указать произвольную строку, а по смыслу туда должно быть введено число. Увы, им пришлось выполнять домашние задания без моих подсказок (впрочем, может быть это совсем не плохо). Но я всё таки решил перед тем, как начнутся занятия следующей группы, написать небольшую “шпаргалку”. Подавляющее большинство книг и статей, где описывается эта техника, в качестве примера рассматривают разбиение на классы множества чисел. При этом совершенно не учитывается тот факт, что в реальных приложениях с пользовательским интерфейсом все поля ввода строковые, и даже если есть ограничения на вводимые символы – это тоже предмет тестирования. А что рекомендуется делать с “нечислами”? Они все объединяются в один большой класс “невалидных” данных, из него наугад берётся одно-два значения и всё. И всё? А вот и нет! Представление о том, что из себя представляет “число” сильно зависит от конкретной реализации, и я покажу вам распространённые примеры строк, которые с точки зрения программы являются числом, хотя не всякий об этом догадается. А также опишу общую схему рассуждений, позволяющую выполнить разбиение на классы эквивалетности для строковых полей ввода, предназначенных для ввода числовых значений. Итак, давайте представим себе, что у нас есть приложение, которое на вход принимает строку, но по смыслу она должна интерпретироваться как число. Например, вот такое: Онлайн-калькулятор для перевода единиц времени.
Все возможные строки, разумеется, можно разделить на два больших класса – “числа” и “нечисла”. Но я дам этим классам другие, более длинные, но при этом более точные названия:
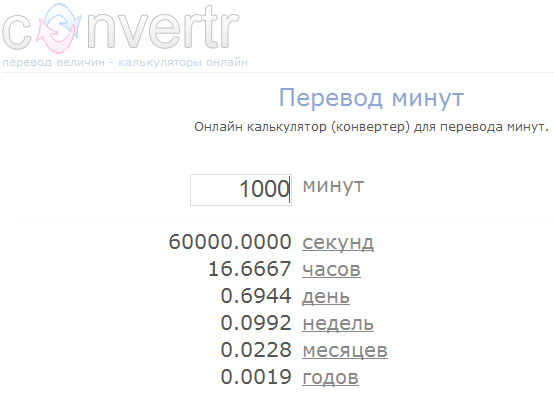
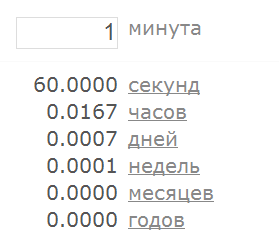
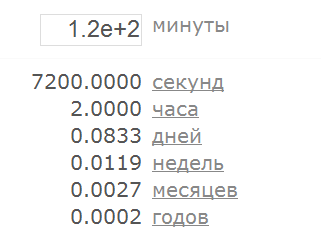
В такой формулировке сразу становится ясно, что программа на вход получает строку, которая перво-наперво по каким-то правилам преобразуется в число. Если это преобразование прошло успешно – полученное число используется в вычислениях, результат которых мы можем наблюдать. А если преобразовать строку в число не удалось – мы получаем информацию об этом либо в виде сообщения о возникшей проблеме, либо в виде “бессмысленного” результата вычислений. Мы можем без труда определить, как именно наш преобразователь времени ведёт себя в той и в другой ситуации, для этого достаточно подать на вход какое-нибудь значение, которое вне всяких сомнений должно интерпретироваться как число (например, “1”):
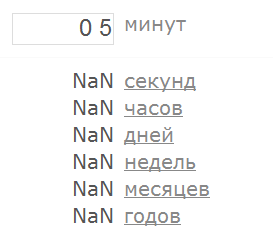
а также какое-нибудь значение, которое абсолютно точно числом не является (например, “привет”):
То есть здесь мы как раз имеем случай, когда “невалидное” входное значение приводить к бессмысленному результату (NaN означает “Not a Number”). Теперь давайте попробуем определить, какие же строки программа будет интерпретировать как числа, то есть начнём выделять в наших больших классах подклассы меньшего размера, но зато описанные конструктивно. Начнём с простого: 1.1. строка, представляющая собой последовательность цифр, интерпретируется как целое число. Очевидно? Вполне. Хотя нет, не совсем очевидно. Наверняка вы уже готовы были поймать меня за руку – какой длины последовательность цифр интерпретируется как число? Всё верно, правильный вопрос. Чтобы ответить на него, нужно опять применить технику разбиения на подобласти. Впрочем, здесь мы как раз имеем достаточно простой случай – длина последовательности это целое неотрицательное число, так что техника работает в полном соответствии с учебниками. Минимальная длина последовательности – ноль. Максимальная длина – “сколько влезет”. А сколько влезет? И куда влезет? В обсуждаемом приложении не указано никаких ограничений на размер поля ввода. Может быть браузер накладывает какое-нибудь ограничение, но лично мне про это ничего не известно, и даже если оно есть – наверняка в разных браузерах оно разное. Если введённые данные передаются на сервер в виде GET-запроса, возможно, имеется ограничение на длину запроса – согласно стандарту RFC 2068 они должны поддерживать не менее 255 байтов, но конечно же все реально способны обрабатывать запросы большей длины, и конечно же это опять зависит от браузера и от веб-сервера. Конвертер, который мы используем в качестве примера, реализован на языке JavaScript, на сервер никаких данных не отправляется, все вычисления производятся внутри браузера. Установленный на моём ноутбуке Google Chrome успешно справился со строкой, состоящей из 10 000 000 девяток, а вот строку из 100 000 000 девяток он обработать уже не смог – после длительного раздумья он вывел сообщение “Опаньки…” и предложил перегрузить страницу, потому что на ней возникла ошибка. Следовательно, где-то между этими значениями и находится та самая максимальная длина, определяемая по принципу “сколько влезет”. Поэтому уточняем: 1.1. строка, представляющая собой последовательность цифр, интерпретируется как целое число, если длина строки не превышает некоторое Максимальное Значение. Впрочем, куда раньше, на существенно более коротких последовательностях, начинает наблюдаться вот такая картина (скриншот показывает ситуацию, когда введена последовательность из 1000 девяток):
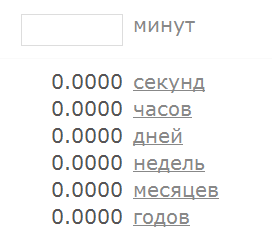
При вычислениях возникло переполнение, однако Infinity – это не NaN, то есть согласно описанном выше уговору мы будем считать, что такая последовательность (а также и более длинные последовательности цифр) всё таки может считаться числом. А что там с другой стороны? Последовательность нулевой длины – это пустая строка. Число ли это? Чуства и логика подсказывают, что нет, однако приложение не согласно с ними и интерпретирует пустую строку как число ноль:
На всякий случай ещё проверим последовательности длины 1, как ближайшей к минимальной граничной. Только чур не пытайтесь найти такую длину, при которой ещё не происходит переполнения, потому что это уже к длине не имеет никакого отношения, здесь важна уже не длина последовательности цифр, а само значение числа. Это оставим читателю в качестве упражнения (подсказка: JavaScript реализует стандарт IEEE-754 и может работать с числами двойной точности), а сами вернёмся к рассмотрению разных других строк. С последовательностями цифр мы разобрались. Давайте попробуем добавить какие-нибудь “нецифры”. Перестанет ли строка быть числом? Наверняка вы сами без труда вспомните некоторые случаи, когда этого (может быть) не случится – пробелы в начале и в конце, а также ведущие нули. Действительно, они обрезаются, а оставщаяся строка интерпретируется как число. Итак: 1.2 строка, интерпретируемая как число, также интерпретируется как число, если добавить в начале некоторое количество нулей, при этом ведущие нули игнорируются, 1.3. строка, интерпретируемая как число, также интерпретируется как число, если добавить в начале или в конце некоторое количество пробелов, при этом все пробелы игнорируются. Всё верно? Нет! Во-первых, не забывайте про Максимальное Значение длины, если добавить слишком много нулей или пробелов, строка перестанет быть числом, даже если эти пробелы добавлялись к совершенно безобидному небольшому числу. Во-вторых, добавлять пробелы и нули можно только в строго определённом порядке — пробелы с краю, нули ближе к «основной части» числа, в другом порядке они уже не будут игнорироваться:
Да, можно эти правила уточнить, ввести понятие “неразрывной последовательности цифр”, к которой уже можно прибавлять пробелы. Но если вы собрались сейчас записать эти правила и повесить на стенку – не делайте этого! Вот вам пример приложения которое действует в точности наоборот – там можно вставлять пробелы куда угодно, хоть в начало, хоть в конец, хоть в середину. А есть и такие (в основном десктопные), в которых пробелы никуда нельзя вставлять, например, так ведёт себя диалог задания размера рисунка в графическом редакторе Paint в Windows 7. Ладно, двигаемся дальше – вспоминаем про отрицательные числа: 1.4. строка, интерпретируемая как число, также интерпретируется как число, если добавить в начало знак минус или плюс. Надеюсь про плюс никто не забыл, да? Кстати, между минусом/плюсом и первой цифрой могут быть пробелы. Ну и перед ними тоже, конечно. Гм… Кажется, у нас проблема. Помните ещё про пустую строку? Мы же согласились считать её как бы числом. Зря согласились – если “перед ней” поставить минус или плюс, числа не получается. Ладно, выкидываем пустую строку, будем рассматривать её отдельно, как особый случай, а минимальную длину последовательности цифр объявим равной единице. Кстати, вас не насторожил тот факт, что я перестал говорить “целое число”? В правиле выделения подобласти 1.1 я его написал, а в следующих правилах нет. Всё верно, эти правила работают также и для нецелых чисел. Добавляем новое правило: 1.5. строка, состоящая из двух неразрывных цепочек цифр, разделённых десятичной точкой, интерпретируется как число Углубляться в подробности, связанные с точностью вычислений не станем, отметим лишь, что здесь тоже можно применить технику разбиения на подобласти. К чему применить? К количеству значащих цифр, или к количеству знаков после запятой, в зависимости от того, как интерпретируется понятие точности в конкретном приложении. Но при этом следует отметить, что для чисел с плавающей точкой техника разбиения на подобласти работает плохо, за подробностями я отправляю вас к статьям Виктора Кулямина про тестирование математических функций (нетерпеливые могут сразу заглянуть в конец раздела 4.3, а любопытные могут поискать ещё другие статьи и презентации на ту же тему на личной страничке Виктора). А всё почему? Потому что JavaScript реализует стандарт IEEE-754. Вообще-то к этому моменту вы, наверное, догадались, что я неспроста уже второй раз упомянул этот стандарт. Да, вы правы. Пришло время перейти к более сложным строкам, которые ну совсем не последовательности цифр, но при этом всё равно интерпретируются как числа. Давайте введём в наше приложение, например, число 120:
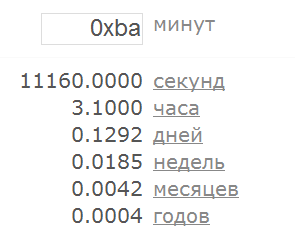
Оно работает! Думаете, это только этот конвертер такой, что я специально его выбрал? Ничего подобного! Откройте с десяток наугад выбранных веб-магазинов или онлайн-калькуляторов – добрая половина согласится принять числа в таком формате. А теперь сходите и проверьте своё собственное приложение. Хотя нет, подождите. Это ещё не всё. Во-первых, надо добавить ещё одно правило: 1.6. строка, состоящая из числа, за которым следует символ ‘e’, за которым следует целое число, интерпретируется как число Да, 100e-1 = 10, а плюс можно не указывать, так что 1.0e2 = 1.0e+2 = 100. А во-вторых, есть ещё и другие строки, которые тоже интерпретируются как числа, вот пример:
Все числа до этого момента у нас были в десятеричном представлении, а теперь появились шестнадцатеричные. Я намеренно в самом начале, когда ещё первый раз сформулировал правило 1.1 не стал акцентировать внимание на том, что такое “цифра”. Что же, добавляем новое правило: 1.7. строка, состоящая из символов ‘0x’, за которыми следует неразрывная последовательность шестнадцатеричных цифр, интерпретируется как шестнадцатеричное целое число Правило 1.1 при этом придётся тоже уточнить, указав, что там могут участвовать только десятеричные цифры. Приятной новостью является то, что шестнадцатеричные числа могут быть только целые (ну, то есть, в этом приложении так, может быть где-то и дробные бывают). Так что максимум, что можно ещё сделать с ними – добавить плюс/минус, да пробелы в начале и в конце. Ну вот, теперь можете проверять своё приложение, сразу и на числа с плавающей точкой, и на шестнадцатеричные числа. А я тем временем расскажу ещё кое-что про строки, которые могут быть числами. Если ваше приложение написано на языке Pascal или Delphi, думаю, вам будет полезно знать, что в этом языке представляются в несколько ином виде – впереди стоит знак $ (доллар), а не 0x. Однажды мне встретился интернет-магазин, который принимал не только числа в шестнадцатеричном представлении, но и в восьмеричном. То есть ноль в начале не игнорировался, как это бывает обычно, а свидетельствовал о том, что число следует интерпретировать как восьмеричное. Так что правило 1.2 тоже не надо вешать на стенку, и оно не всегда справедливо. Попробуйте в наш подопытный конвертер ввести строку Infinity – вы удивитесь, но это тоже число (а в некоторых языках программирования распознаётся также строка Inf):
В качестве записной книжки для ведения списка дел я использую замечательный сервис Toodledo. Так вот, там при создании записи можно в поле ввода даты написать, например, “tomorrow” или “next Monday” – и оно работает! Для таких преобразований бывают даже специальные библиотеки, например, в языке Perl для анализа дат используется Date::Manip, а для анализа чисел Lingua::EN::Words2Num. Мне лично не приходилось тестировать приложения, где можно было бы вводить числа в текстовом виде, но такое действительно иногда встречается на практике. Ещё одно любопытное “число”, специально для тех, кто знаком с языком программирования Perl – “0 but true”. А вот пример приложения – калькулятор доходности вкладов, в котором число в шестнадцатеричном представлении проходит валидацию, которая выполняется средствами JavaScript, но вызывает проблемы при вычислениях на серверной стороне. Попробуйте указать сумму вклада в шестнадцатеричном виде, например, 0xff – и вы увидите, что серая табличка с расчётами не появится на странице. Добиться аналогичного эффекта, вводя положительные десятеричные числа, мне не удалось. (Примечание: так работал калькулятор во время написания статьи, сейчас реализация уже изменилась) Этот приём позволяет иногда “протолкнуть” через валидатор неправильное значение, которое может привести к сбоям на серверной стороне. В общем, надеюсь, вы поняли, что “строка, которая может быть проинтерпретирована как число” – это не такая простая штука, как может показаться на первый взгляд. А что же попадает во второй большой класс, “нечисла”. Туда попадает всё остальное. Да, вот такое неконструктивное определение. И при этом я обещал в самом начале статьи рассказать вам общую схему рассуждений, позволяющую выполнить разбиение на классы эквивалетности. Пожалуйста, вот эта схема, в одном абзаце: Сначала считаем, что все строки находятся в классе “нечисел”. Как только вы прочитали в требованиях, или в документации, или узнали от коллег, или прочитали в какой-нибудь статье (например, в этой) о том, что строки определённого вида могут интерпретироваться как число – вы выделяете соответствующее подмножество строк и проверяете. Если оказалось, что ваше приложение не считает строки такого вида числами, вы сбрасываете всё обратно в большой класс “нечисел”. Ну а если приложение всё-таки согласилось считать эти строки числами, тогда они выделяются в отдельный подкласс и переводятся в класс “чисел”. Вот и всё, очень простой алгоритм �� Ну так что, принимает ваше приложение шестнадцатеричные числа или нет, а? Что такое классы эквивалентности?Методика группировки и разделения тестовых входных данных на некие эквивалентные классы. Широко применяемая техника тестирования черного ящика; относится к базовым; всегда спрашивают на собеседованиях. Альтернативное название: эквивалентное разбиение. Как гласит Первый принцип тестирования, “полное тестирование программы невозможно, или займет недопустимо длительное время”. Причина в том, что нужно проверить слишком много комбинаций тестовых данных. Например, слушатель курсов программирования написал простейший калькулятор, и нужно протестировать в нем (хотя бы) все возможные операции сложения (а их 10 в 16 степени, то есть 10 квадриллионов), на это понадобятся миллиарды лет. Классы эквивалентности помогают тестировщику получить четкие результаты за ограниченное время, покрывая множество тестовых сценариев. Улучшается качество тест-кейсов, устраняется избыточность, возможная в других методиках. Особенности
Стандартные действия по методике
ПримерЕсть приложение, принимающее на ввод число из 2 или 3 цифр. Из условия понятно, что диапазон возможных чисел — достаточно большой, и все варианты проверить получается неэкономно.
Еще примерЕсть приложение, в которое подается число от 10 до 100, и затем вычисляется его корень. Эквивалентные классы будут такими:
Типы классов эквивалентности ( * )
Советы
Преимущества и недостаткиПлюсы
Минусы
Разница между классами эквивалентности и анализом граничных значений
Техника эквивалентных классов так важна в тестировании, и настолько часто применяется, что в ISTQB есть отдельный тип тестового покрытия — покрытие эквивалентного разбиения, «процент эквивалентных областей, проверенных набором тестов». Класс эквивалентности «Ноль-не ноль»
Именно в нуле любят собираться ошибки. На сайте вроде просто поле, а где-то внутри система делит на него при подсчете процента покупки. Подставил ноль — все сломалось. Профит! Баг! Или продуман только позитивный сценарий — всегда заказывают больше нуля книг / пицц / настолок. Ввел ноль, а код обработки значения не написан. Опять сломалось… Или оставил поле пустым, а система тебе БАЦ, и эксепшен… Поле ввода — цифры естьТут все просто. Если видим числовое поле, пробуем ноль
Число книг: ноль / не ноль. Кол-во пар обуви: ноль / не ноль. Возраст пациента: ноль / не ноль. Номер заказа: ноль / не ноль. Выручка в рублях: ноль / не ноль. Коэффициент похожести: ноль / не ноль.
Это логично, такую проверку делают многие. Легко найти число в числовом поле! Но что, если поле не числовое? Сразу затык. Длина строки Конечно, можно! Кладем наше поле на числовую ось и получаем класс «длина строки». Та-а-а-ак, допустимое имя по ТЗ — от 3 до 6 символов. Окей, а как насчет нуля? Что будет, если оставить строку пустой? Так мы применяем класс «ноль-не ноль». Длина имени: ноль / не ноль. Длина эл почты: ноль / не ноль. Длина пароля: ноль / не ноль. Длина названия организации: ноль / не ноль. Состояние объекта — цифр нетЛегко подставить ноль туда, где есть цифры. Несложно положить символьную строку на числовую ось и найти границы по длине строки. Что будет, если оставить строку пустой? А если заполнить? А если ввести только один символ (пограничное значение)? Число книг: ноль / не ноль. Символов в имени: ноль / не ноль. Сложно применить класс «ноль / не ноль» там, где вроде бы нет цифр. И даже длины строки нет. В итоге тестировщик Вася ловит баг, но не может потом воспроизвести. Потому что не локализовал, не нашел точное условие → не записал его в шаги → задачу отложили → спустя месяц по шагам автора уже не воспроизводится, потому что его учетку удалили. А проблема была в ней, ведь Вася оплачивал продукты по PayPal до того, как возможность прикрыли. И забыли отмигрировать данные. На новой учетке даже возможности оплатить по PayPal нету (ноль) → баг не воспроизведется, ведь нам нужна учетка, где количество оплат по PayPal «не ноль». И сидят Вася с Петей-разработчиком, копаются в логах, пытаются понять, как воспроизвести проблему. Или еще хуже — пожимают плечами, «А! Видимо, само починилось в рамках другой задачи» и закрывают баг как Cannot reproduce. И душа спокойна — теперь то работает! До тех пор, пока у реального пользователя баг не выстрелит. И тогда начнется паника, БЛОКЕР-приоритеты и все такое. А потом Петя поймет, в чем дело было, да даст Васе подзатыльник — сразу надо было про «ноль-не ноль» думать! Учитесь видеть «ноль-не ноль» не только в числах и длине строк, но и в состояниях объекта: Пользователь авторизован / не авторизован. Заходил на сайт ранее / не заходил. Заполнял профиль / не заполнял. Аватарку загружал / не грузил. Деньги снимал / не снимал. Это самые крутые примеры класса, потому что о них не задумываются. Их пропускают. И именно поэтому их надо проверять. Как при поиске багов, так и при локализации конкретной ошибки: «Так-с, упало. А это всегда так или только при первом просмотре (раньше не смотрел — ноль, уже видел — не ноль)?». Ноль на выходеНе забывайте — ноль может быть не только на входе, но и на выходе! — Ввести ноль в числовое поле, — Оставить строку символов пустой. — После совершения покупки баланс уйдет в ноль. — После обработки поле станет пустым. — Поиск вернет ноль результатов (хотя на входе у нас непустая строка поиска). — Отчет на указанную дату будет пустым (опять же, дата на входе была указана не-ноль). ПримерПосмотрим на примере Дадаты. Там куча нестандартных мест для проверки нашего класса «ноль-не ноль». При регистрации у нас три унылых символьных поля, там все просто — поле заполнено или нет. Давайте найдем все классы с нулем для обработки файлов! После авторизации появляется форма загрузки — https://dadata.ru/clean/.
Выбираем файл — Дадата отображает структуру. Если она вдруг неправильно определила тип, его всегда можно изменить в выпадающем списке:
Проверив структуру, переходим к предварительному результату. Если все ок, оплачиваем и получаем итоговый файл.
— Файл может быть пустой: ноль строк, ноль колонок. Ок. — Система распознает первую строку как шапку. А что, если у нас будет ноль «значимых» строк? — Мы платим за обработку — а что, если у нас ноль рублей на счету? А что, если после обработки у нас станет ноль или даже меньше? Помним о том, что ноль может быть не только на входе, но и на выходе. — А что, если у нас на выходе будет ноль данных? Если мы под видом ФИО пришлем фигню из серии “12345”? Да, колонки будут, но пустые же! — А что, если на выходе вообще ничего? Присмотритесь к структуре, там же есть кнопка «Исключить столбец»! А что, если мы исключим все столбцы и получим на выходе ноль?
Проверьте себя, найдите все нули в: — форме обработки по одному человеку; Чур, спойлеры в комментах не писать! =) Просто в следующий раз, тестируя свою систему, вспомните о том, что ноль есть не только в числах и длинах полей. Ищите его там, где другие не ищут!Другие примеры: Что такое классы эквивалентности?�� Какой была ваша первая зарплата в QA и как вы искали первую работу? Мега-обсуждение в нашем телеграм-канале. Что такое классы эквивалентностиКоротко: выбранные тестировщиком наборы данных (диапазоны), которые подаются на ввод в модуль, и это должно приводить к одинаковым результатам. Методика группировки и разделения тестовых входных данных на некие эквивалентные классы. Широко применяемая техника тестирования черного ящика; относится к базовым; всегда спрашивают на собеседованиях. Альтернативное название: эквивалентное разбиение. Как гласит Первый принцип тестирования, “полное тестирование программы невозможно, или займет недопустимо длительное время”. Причина в том, что нужно проверить слишком много комбинаций тестовых данных. Например, слушатель курсов программирования написал простейший калькулятор, и нужно протестировать в нем (хотя бы) все возможные операции сложения (а их 10 в 16 степени, то есть 10 квадриллионов), на это понадобятся миллиарды лет. Классы эквивалентности помогают тестировщику получить четкие результаты за ограниченное время, покрывая множество тестовых сценариев. Улучшается качество тест-кейсов, устраняется избыточность, возможная в других методиках. Особенности
Стандартные действия по методике
ПримерЕсть приложение, принимающее на ввод число из 2 или 3 цифр. Из условия понятно, что диапазон возможных чисел — достаточно большой, и все варианты проверить получается неэкономно.
Еще примерЕсть приложение, в которое подается число от 10 до 100, и затем вычисляется его корень. Эквивалентные классы будут такими:
Типы классов эквивалентности ( * )
Советы
Преимущества и недостаткиПлюсы
Минусы
Разница между классами эквивалентности и анализом граничных значений
Техника эквивалентных классов так важна в тестировании, и настолько часто применяется, что в ISTQB есть отдельный тип тестового покрытия — покрытие эквивалентного разбиения, «процент эквивалентных областей, проверенных набором тестов». |