2. Понятие об эмпирических формулах. Метод наименьших квадратов.
В практических применениях математики часто встречается такая задача: зависимость между переменными величинами выражается в виде таблицы, полученной опытным путем. Это могут быть результаты эксперимента, данные наблюдений или измерений, статистической обработки материала и т.п. Требуется выразить эту зависимость между переменными аналитически, т.е. дать формулу, связывающую между собой соответствующие значения переменных. Такая формула облегчает анализ изучаемой зависимости.
Формулы, служащие для аналитического представления опытных данных называются эмпирическими формулами.
Нужно иметь в виду, что подбор эмпирической формулы по данным результатам наблюдений не может ставить перед собой задачу разгадать истинный характер зависимости
между имеющимися переменными, тем более, что экспериментальные данные наверняка содержат случайные ошибки измерения или статистических наблюдений.
Применяются два различных метода построения эмпирических формул:
Интерполяция– когда строится многочлен, принимающий в заданных точках заданные значения. Достоинство этого метода в том, что полученная формула в точности воспроизводит заданные значения.
Аппроксимация (приближение, сглаживание) – когда по данным результатам наблюдений подбирается наиболее простая формула того или иного типа, дающая наилучшее приближение к имеющимся данным. При этом формула не воспроизводит в точности данные наблюдений.
Для получения аппроксимирующей функции чаще всего используется метод наименьших квадратов.
Пусть в результате эксперимента получено n значений функции при соответствующих значениях аргумента. Результаты записаны в таблицу.
при соответствующих значениях аргумента. Результаты записаны в таблицу.










Требуется установить функциональную зависимость величины  от величины
от величины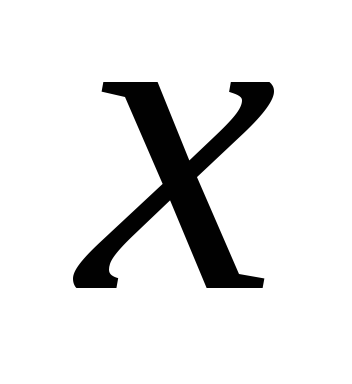 :
: . Задача разбивается на два этапа.
. Задача разбивается на два этапа.
1. Из теоретических соображений или с помощью графического представления экспериментальных точек устанавливают вид зависимости  , т.е. решают, является она линейной
, т.е. решают, является она линейной , квадратичной
, квадратичной , показательной
, показательной и т.д.
и т.д.
Если точки расположены как на рис.9, то вид функции линейный  , если как на рис.10, то вид зависимости показательный
, если как на рис.10, то вид зависимости показательный или
или .
.


2. Определяют неизвестные параметры методом наименьших квадратов.
Суть метода: находим отклонения  экспериментальных значений
экспериментальных значений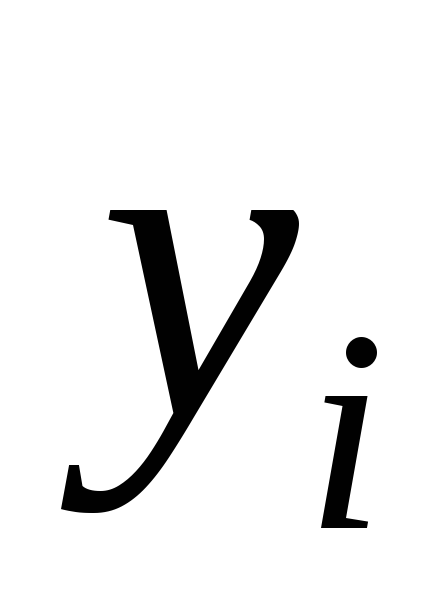 от теоретических, вычисленных по формуле
от теоретических, вычисленных по формуле . Составляем функцию
. Составляем функцию – сумма квадратов отклонений. Неизвестные параметры определяем так, чтобы сумма была наименьшей, т.е.
– сумма квадратов отклонений. Неизвестные параметры определяем так, чтобы сумма была наименьшей, т.е. .
.
2.2 Определение параметров линейной зависимости методом наименьших квадратов.
Пусть вид зависимости линейный 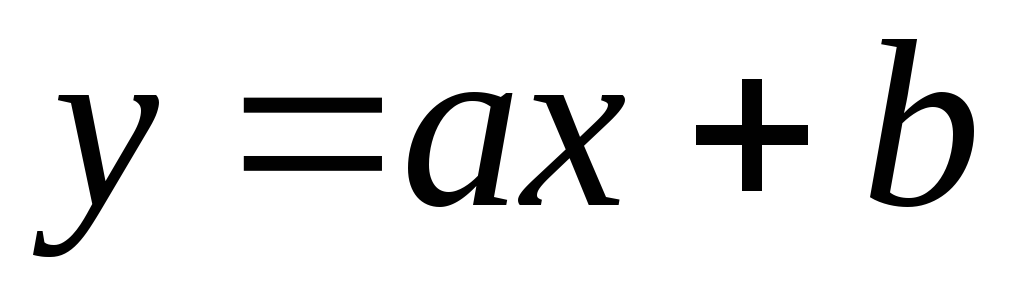 . Задача – определить параметрыа иb, чтобы функция наилучшим образом описывала рассматриваемый процесс.
. Задача – определить параметрыа иb, чтобы функция наилучшим образом описывала рассматриваемый процесс.
Рассмотрим функцию.  , где
, где
 — разность между экспериментальным значением и значением, определяемым функцией
— разность между экспериментальным значением и значением, определяемым функцией 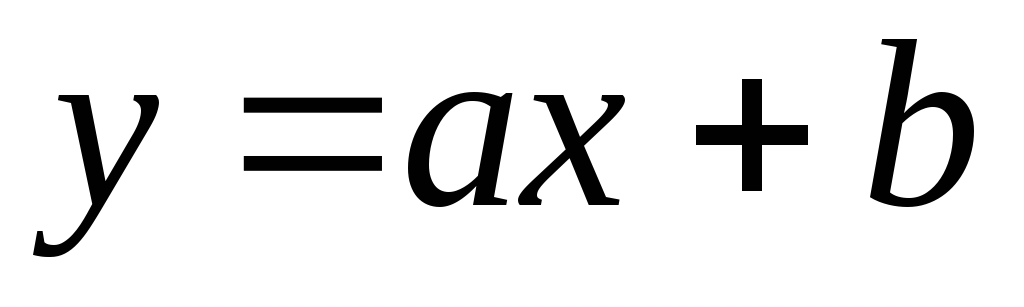 .
.
Получили функцию  двух переменныха иb. Параметрыа иbнужно подобрать так, чтобы сумма имела наименьшее значение (отклонение экспериментальных точек от прямой было минимальным). При любых значенияха иb
двух переменныха иb. Параметрыа иbнужно подобрать так, чтобы сумма имела наименьшее значение (отклонение экспериментальных точек от прямой было минимальным). При любых значенияха иb  . Поэтому, если эта функция имеет экстремум, то это будет минимум. Функция
. Поэтому, если эта функция имеет экстремум, то это будет минимум. Функция  будет иметь минимум в точках, в которых частные производные равны нулю:
будет иметь минимум в точках, в которых частные производные равны нулю:
 .
.  ,
,
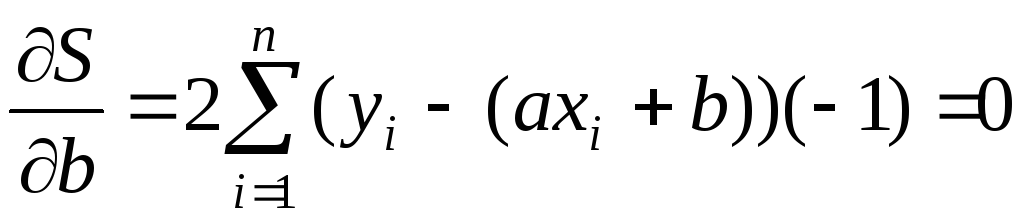 .
.
Преобразуя эти уравнения, получим систему, которая называется нормальной:
 .
.
Это система линейных уравнений с двумя неизвестными а иb, решая её любым способом, найдем коэффициенты эмпирической формулы .
.
Пример выполнения РГР.
Результаты измерений представлены таблицей. Методом наименьших квадратов составить эмпирическую формулу, выражающую зависимость между хиy.
Методы подбора эмпирических формул
В процессе экспериментальных исследований получается статистический ряд измерений двух величин, когда каждому значению функции y1, у2, …, уn соответствует определенное значение аргумента х1, х2, …, хn..
На основе экспериментальных данных можно подобрать алгебраические выражения функции
которые называют эмпирическими формулами. Такие формулы подбираются лишь в пределах измеренных значений аргумента x1 – хn и имеют тем большую ценность, чем больше соответствуют результатам эксперимента.
Необходимость в подборе эмпирических формул возникает во многих случаях. Так, если аналитическое выражение (7) сложное, требует громоздких вычислений, составления программ для ЭВМ или вообще не имеет аналитического выражения, то эффективнее пользоваться упрощенной приближенной эмпирической формулой.
Эмпирические формулы должны быть по возможности наиболее простыми и точно соответствовать экспериментальным данным в пределах изменения аргумента. Таким образом, эмпирические формулы являются приближенными выражениями аналитических формул. Замену точных аналитических выражений приближенными, более простыми называют аппроксимацией, а функции – аппроксимирующими.
Процесс подбора эмпирических формул состоит из двух этапов.
I этап. Данные измерений наносят на сетку прямоугольных координат, соединяют экспериментальные точки плавной кривой и выбирают ориентировочно вид формулы.
II этап. Вычисляют параметры формул, которые наилучшим образом соответствовали бы принятой формуле. Подбор эмпирических формул необходимо начинать с самых простых выражений. Так, например, результаты измерений многих явлений и процессов аппроксимируются простейшими эмпирическими уравнениями типа
у = а + bх, (8)
где a, b – постоянные коэффициенты. Поэтому при анализе графического материала необходимо по возможности стремиться к использованию линейной функции. Для этого применяют метод выравнивания, заключающийся в том, что кривую, построенную по экспериментальным точкам, представляют линейной функцией.
Для преобразования некоторой кривой (7) в прямую линию вводят новые переменные
В искомом уравнении они должны быть связаны линейной зависимостью
Y = а + bX. (10)
Значения X и Y можно вычислить на основе решения системы уравнений (9). Далее строят прямую (рис. 8), по которой легко графически вычислить параметры а (ордината точки пересечения прямой с осью Y) и b (тангенс угла наклона прямой с осью X): b = tga = (Yi – a)/Xi.
При графическом определении параметров а и b необходимо, чтобы прямая (8) строилась на координатной сетке, у которой началом является точка Y = 0 и
X = 0. Для расчета необходимо точки Yi и Xi принимать на крайних участках прямой.
 |
Рис. 8. Графическое определение параметров X и Y
Для определения параметров прямой можно применить также другой графический метод. В уравнение (10) подставляют координаты двух крайних точек, взятых с графика. Получают систему двух уравнений, из которых вычисляют а и b. После установления параметров а и b получают эмпирическую формулу (8), которая связывает Y и X, позволяет установить функциональную связь между х и у и эмпирическую зависимость (7).
Линеаризацию кривых можно легко осуществить на полулогарифмических или логарифмических координатных сетках, которые сравнительно широко применяют при графическом методе подбора эмпирических формул.
Пример. Подобрать эмпирическую формулу следующих измерений:
12,1 19,2 25,9 33,3 40,5 46,4 54,0
Графический анализ этих измерений показывает, что в прямоугольных координатах точки хорошо ложатся на прямую линию и их можно выразить зависимостью (8). Выбираем координаты крайних точек и подставляем в (8). Тогда A0 + 7 A1 = 54,0; A0 + 1 A1 = 12,1, откуда А1 = 41,9: 6 = 6,98 и А0 = 12,1 – 6,98 = 5,12. Эмпирическая формула примет вид
y = 5,12 + 6,98 х.
Таким образом, аппроксимация экспериментальных данных прямолинейными функциями позволяет просто и быстро установить вид эмпирических формул.
Графический метод выравнивания может быть применен в тех случаях, когда экспериментальная кривая на сетке прямоугольных координат имеет вид плавной кривой. Так, если экспериментальный график имеет вид, показанный на рис. 9а, то необходимо применить формулу

Рис. 9. Основные виды графиков эмпирических формул
Заменяя X = lg х и Y = lg у, получим Y = lg a – bХ. При этом экспериментальная кривая превращается в прямую линию на логарифмической сетке. Если экспериментальный график имеет вид, показанный на рис. 9б, то целесообразно использовать выражение
у = а ·е . (12)
При замене Y = lg у получим Y = lg a + bx lg e. Здесь экспериментальная кривая превращается в прямую линию на полулогарифмической сетке. Если экспериментальный график имеет вид, представленный на рис. 9в, то эмпирическая формула принимает вид
у = с + ах b . (13)
Если b задано, то надо принять X = х b , и тогда получим прямую линию на сетке прямоугольных координат Y = с + а X. Если же b неизвестно, то надо принять X = lg х и Y = lg (y – с), в этом случае будет прямая линия, но на логарифмической сетке Y = lg a + bХ. В последнем случае необходимо предварительно вычислить с. Для этого по экспериментальной кривой принимают три произвольные точки (х1, у1), (х2, у2), и (х3 = , y3) ивычисляют с в виде отношения
Если экспериментальный график имеет вид, показанный на рис. 9.4г, то нужно пользоваться формулой
y = с + а e bx . (15)
Путем замены Y = lg (у – с) можно построить прямую на полулогарифмической сетке
Y = lg a + bx lg c,
где с предварительно определено с помощью формулы (14). В этом случае
Если экспериментальный график имеет вид, представленный на рис. 9.4д, то применяется выражение
у = а + b/х. (16)
Путем замены х = 1 / z можно получить прямую линию на сетке прямоугольных координат у = а + bz.
Если график имеет вид, соответствующий кривым на рис. 9е, то используют формулу
y = 1/(a + bx). (17)
Если принять новую функцию у = 1/z, где z = а + bх, то получится прямая на сетке прямоугольных координат «z – х».
y = 1/(а + bх + сх 2 ) (18)
путем замены y = 1/z можно придать вид параболы z = а + bх + сх 2 .
Сложную степенную функцию
можно преобразовать в более простую. При lg у = z; lg a = р; п lg e = q;
т lg е = r получается зависимость
z = р + qx + r х 2 .
С помощью приведенных на рис. 9 графиков и выражений (11 – 19) можно практически всегда подобрать уравнение эмпирической формулы.
Пример. Необходимо подобрать эмпирическую формулу для следующих измерений:
1 1,5 2,0 2,5 3,0 3,5 4,0 4,5
15,2 20,6 27,4 36,7 49,2 66,0 87,4 117,5
На основе этих данных строится график (рис. 9а), соответствующий кривым (12) (рис. 9б).
После логарифмирования выражения (12) lg у = lg a + bx lg e. Если обозначить lg у = Y, то Y = lg a + bx lg e, т. е. в полулогарифмических координатах выражение для Y представляет собой прямую линию (рис. 10). Подстановка в уравнение координат крайних точек дает
lg 15,2 = lg a +b lg е и lg 117,5 = lg a + 4,5 b lg e.
Следовательно, lg a + b lg е = 1,183; lg a + 4,5 b lg e = 2,070.
Откуда b = 0,887/(3,5 lg e) = 0,583; lg a =1,183 – 0,254 = 0,929; a = 8,492. Окончательно эмпирическая формула получит вид
У = 8,492 е .
При подборе эмпирических формул широко используются полиномы
у = Ао + А1 х + А2 х 2 + А3 х 3 +. +Аn х n (20)
где Ао, A1. Аn – постоянные коэффициенты. Полиномами можно аппроксимировать любые результаты измерений, если они графически выражаются непрерывными функциями. Особо ценным является то, что даже при неизвестном точном выражении функции (20) можно определить значения коэффициентов А. Для определения коэффициентов А кроме графического метода, изложенного выше, применяют также методы средних и наименьших квадратов.
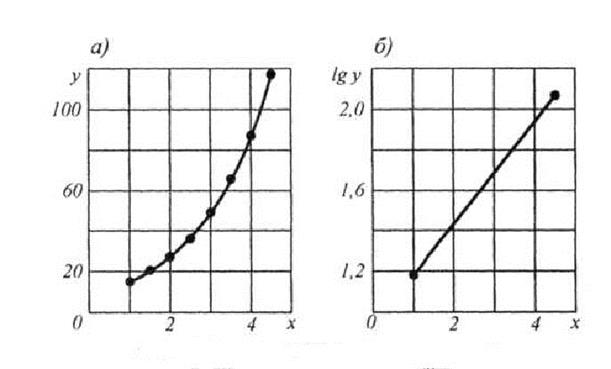
Рис. 10. Подбор эмпирической характеристики:
а – эмпирическая; б – спрямленная
9.4. Элементы теории планирования эксперимента
Математическая теория эксперимента определяет условия оптимального проведения исследования, в том числе и при неполном знании физической сущности явления. Для этого используются математические методы при подготовке и проведении опытов, что позволяет исследовать и оптимизировать сложные системы и процессы, обеспечивать высокую эффективность эксперимента и точность определения исследуемых факторов. Обеспечивается также эффективное управление экспериментом при неполном знании механизма явлений.
Эксперименты обычно ставятся небольшими сериями по заранее согласованному алгоритму.
После каждой небольшой серии опытов производится обработка результатов наблюдений и принимается строго обоснованное решение о том, что делать дальше.
При использовании методов математического планирования эксперимента возможно решать различные вопросы, связанные с изучением сложных процессов и явлений; проводить эксперимент с целью адаптации технологического процесса к изменяющимся оптимальным условиям его протекания и обеспечивать, таким образом, высокую эффективность его осуществления и др.
Теория математического эксперимента содержит ряд концепций, которые обеспечивают успешную реализацию задач исследования. К ним относятся концепции рандомизации, математического моделирования, последовательного эксперимента, оптимального использования факторного пространства и ряд других.
Принцип рандомизации заключается в том, что в план эксперимента вводят элемент случайности. Для этого план эксперимента составляется таким образом, чтобы те систематические факторы, которые трудно поддаются контролю, учитывались статистически и затем исключались в исследованиях как систематические ошибки.
При последовательном проведении эксперимент выполняется не одновременно, а поэтапно, с тем, чтобы результаты каждого этапа анализировать и принимать решение о целесообразности проведения дальнейших исследований (рис. 11).
В результате эксперимента получают уравнение регрессии, которое часто называют моделью процесса. Для конкретных случаев математическая модель создается исходя из целевой направленности процесса и задач исследования, с учетом требуемой точности решения и достоверности исходных данных, что обычно производится по критерию Фишера. Так как степень полинома, адекватно описывающего процесс, предсказать невозможно, то сначала пытаются описать явление линейной моделью, а затем, если она неадекватна, повышают степень полинома, т. е. проводят эксперимент поэтапно.
В настоящее время изданы каталоги планов эксперимента, например каталог планов, выпущенный Московским государственным университетом, в которых приводится сравнительная оценка планов и рекомендации по их выбору применительно к конкретным условиям эксперимента.
Важное место в теории планирования эксперимента занимают вопросы оптимизации исследуемых процессов, свойств многокомпонентных систем или других объектов. Как правило, нельзя найти такое сочетание значений влияющих факторов, при котором одновременно достигается экстремум всех функций отклика. Например, максимальный крутящий момент двигателя и минимальный расход топлива достигаются при различных режимах работы. Поэтому в большинстве случаев за критерий оптимальности выбирают лишь одну из переменных состояния − функцию отклика, характеризующую процесс, а остальные принимают приемлемыми для данного случая. Методы планирования эксперимента в настоящее время быстро развиваются, чему способствует возможность широкого использования ЭВМ.
Рис. 11. Структурная схема эксперимента:
а – с целью математического описания исследуемого процесса; б – с целью оптимизации исследуемого процесса
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Что такое эмпирическое правило в инференциальной статистике?

Инференциальная статистика фокусируется на вероятности наступления событий на основе данных наблюдений. В этой области статистики также применяются принципы, которые определяют, как вычислять различные меры в рамках функций вероятности. Эмпирическое правило — это один из принципов, которому часто следуют аналитики данных и статистики при структурировании параметров для исследования и анализа.
В этой статье мы обсудим, что такое эмпирическое правило, опишем, как использовать его для вероятности, рассмотрим, как рассчитать стандартное отклонение в соответствии с правилом, и перечислим, в каких областях часто применяется правило для статистического анализа.
Что такое эмпирическое правило?
Эмпирическое правило или правило трех сигм — это принцип, согласно которому почти все данные наблюдений в рамках нормального распределения должны появляться в пределах первых трех стандартных отклонений от среднего значения данных. Предполагая нормальное распределение данных вокруг среднего значения, расчет эмпирической вероятности приводит к колоколообразной кривой, где вершина колокол является средним значением данных.
Поскольку кривая наклоняется вниз по обе стороны, левая часть графика представляет собой отрицательные стандартные отклонения, а правая — положительные стандартные отклонения. Используя это правило, стандартные отклонения следуют правилу 68-95-99.7 правило, где:
Стандартные отклонения от нуля до единицы содержат 68% данных для значений (0 — (-1)) и (0 — 1)
От одного до двух стандартных отклонений содержат 95% данных для значений ((-1) — (-2)) и (1 — 2)
От двух до трех стандартных отклонений 99.7% данных для значений ((-2) — (-3)) и (2 — 3)
Как использовать эмпирическое правило?
Обычно правило используется при вычислении эмпирической вероятности возникновения наблюдений, поскольку эмпирический принцип всегда предполагает нормальное распределение. Таким образом, вы можете использовать это правило для расчета колоколообразной кривой, где ваши данные попадают в пределы каждого стандартного отклонения, поскольку они следуют по схеме 68-95-99.7 правило. В качестве примера предположим, что вы записываете свой пульс в состоянии покоя в течение семи дней. Согласно правилу эмпирической вероятности, средняя частота сердечных сокращений находится в верхней части кривой, где:
Стандартное отклонение от среднего равно нулю
34% сердечных сокращений попадают в пределы (0 — (-1)) и (0 — 1) стандартных отклонений
13.5% сердечных сокращений попадают в пределы ((-1) — (-2)) и (1 — 2) стандартных отклонений
2.35% сердечных сокращений находятся в пределах ((-2) — (-3)) и (2 — 3) стандартных отклонений
Если вы хотите рассчитать вероятность того, что ваш пульс попадет в определенный диапазон, вы можете построить график среднего значения и разделить кривую на стандартные отклонения в соответствии с правилом.
Как эмпирическое правило применяется в профессиональных областях?
Эмпирическое правило вероятности применяется одинаково во многих приложениях, поскольку это эффективный инструмент для оценки будущих результатов на основе данных, собранных в ходе повторных наблюдений. Рассмотрим, как представители нескольких профессий применяют эмпирические правила вероятности:
Финансы и бухгалтерский учет: Финансовые аналитики часто применяют эмпирический принцип при создании прогнозов, поскольку они могут отслеживать финансовую историю и использовать статистический анализ для определения средних значений, стандартных отклонений и эмпирической вероятности для установления целей прибыльности.
Маркетинговая аналитика: Маркетинговые аналитики могут оценить эмпирическую вероятность стратегий, которые они реализуют в кампаниях, используя данные о потребителях для прогнозирования будущих тенденций, которые могут помочь им улучшить интеграцию стратегий.
Здравоохранение: Клинические исследователи часто используют эмпирические вероятности в медицинских исследованиях, которые помогают специалистам здравоохранения понять потенциальные результаты таких вещей, как методы лечения и новые лекарства.
Образование: Специалисты в области образования также применяют эмпирические правила для оценки результатов обучения студентов и стандартизированных оценок, чтобы установить прогностические критерии для сравнения с будущими результатами.
Технология: Многие приложения в области данных и компьютерных наук полагаются на выводную статистику и эмпирическую вероятность для завершения таких проектов, как создание автоматизированных систем, тестирование компьютерных программ и создание программного обеспечения.
Что такое нормальное распределение?
Нормальное распределение, или распределение Гаусса, относится к симметричному распределению данных вокруг среднего значения. Это вероятностная статистика, которая показывает, что ближе к среднему значению происходит больше наблюдений, чем дальше от него.
Это распределение создает колоколообразную кривую, когда вы строите график функции вероятности. В статистике нормальное распределение всегда предполагает такую дисперсию данных. Поэтому применение правила эмпирической вероятности требует, чтобы все собранные вами данные следовали этому параметру распределения.
Как определить стандартное отклонение?
Выполните следующие действия, чтобы рассчитать стандартное отклонение набора данных:
1. Найдите среднее значение
Вычислите среднее или среднее значение вашего набора данных. Это значение также находится в верхней части колоколообразной кривой нормального распределения. Например, вычисление среднего значения набора данных <1.12, 1.34, 1.57, 1.89, 2.09>дает вам среднее значение (8.01 5), что равно 1.6. Различные наборы данных имеют различные средние значения, основанные на значениях внутри этих наборов данных.
2. Вычтите среднее значение из каждого значения
Когда вы получите среднее значение, найдите разницу между ним и каждым значением в вашем наборе данных. Вычитание дает новые значения, квадрат которых вы берете позже. С набором данных примера и средним значением 1.6, вычитание среднего из каждого значения приводит к <-0.48, -0.26, -0.03, 0.29, 0.49>.
3. Возведите в квадрат каждую разность
После вычитания среднего из всех значений в выборке, возведите каждое из них в квадрат. При возведении числа в квадрат возведите его в степень с показателем два. Для примера набора данных возведение в квадрат каждой разницы дает <0.23, 0.06, 0.0009, 0.24>.
4. Найдите среднее значение разности квадратов
Когда вы получите результаты, вычислите среднее значение каждого значения, которое вы возвели в квадрат. Это дает новое среднее значение, из которого вы берете стандартное отклонение. Вычисление квадратов для примера приводит к новому среднему значению 0.53.
5. Вычислите квадратный корень из нового среднего значения
Согласно эмпирическому принципу, стандартное отклонение должно находиться в пределах первых трех стандартных отклонений от среднего значения исходного набора данных. Чтобы определить это, возьмите квадратный корень из среднего значения, полученного на предыдущем этапе. На примере 0.53 дает стандартное отклонение 0.73, которое находится в пределах первых трех положительных стандартных отклонений от среднего значения.
Что является примером эмпирического правила?
Ниже приведен пример использования профессором эмпирического правила:
Профессор хочет использовать правило эмпирической вероятности, чтобы определить, как распределяются результаты тестов в пределах колоколообразной кривой. Профессор находит среднее значение баллов за тест и вычисляет стандартное отклонение. Если средний балл равен 80, а стандартное отклонение равно единице, то образуется колоколообразная кривая:
80 как центр кривой
Первые три стандартных отклонения между (0 — 3) содержат оценки
Первые три стандартных отклонения между (0 — (-3)) содержат оценки
Поскольку первые три стандартных отклонения представляют 68-95-99.7 правило, профессор определяет, что 68% экзаменов получают оценку от 79 до 81, 95% экзаменов получают оценку от 78 до 82 и 99.7% экзаменов получают оценку от 77 до 83 баллов. Это означает, что вероятность того, что на следующем экзамене будет получен балл 78.5 составляет 95%.
В чем преимущества эмпирического правила?
Основное преимущество эмпирического правила заключается в том, что оно может помочь вам классифицировать и прогнозировать данные. Это полезно, потому что вы можете делать точные прогнозы и классифицировать данные из большого набора данных. Например, набор данных с 1 000 записей может создать распределение для данных и показать, какие точки находятся в пределах определенного количества стандартных отклонений.
Что такое эмпирический расчет
К, используется для выявления статистической зависимости величин при обработке данных. Наряду с указанной формулой используется ряд формул эмпирического определения тесноты корреляционной связи между наблюдаемыми признаками исследуемых величин. См. также Ратовал корреляция. [c.155]
Рассчитать параметры формулы эмпирической зависимости анализируемого показателя от выбранного круга показателей. [c.128]
Для вывода формулы на основе хронометражных наблюдений необходимо получить данные о затратах времени при различных значениях количественных факторов, находящихся внутри принятого диапазона их изменения. Количество значений каждого фактора, при которых следует проводить наблюдения, определяют исходя из соотношения его крайних числовых значений. Чем больше это соотношение, тем больше проводят наблюдений. Минимальное количество значений фактора и соответствующих им затрат времени, необходимое для вывода формулы эмпирической зависимости, определяют из выражения [c.109]
Точное аналитическое выражение зависимости между исследуемыми величинами может оставаться неизвестным и поэтому по необходимости приходится ограничиваться приближенными формулами эмпирического характера. [c.40]
Параметрические методы планирования себестоимости основаны на использовании выявленных и отраженных в эмпирических формулах зависимостей размера затрат от параметров продукции и условий производства. Из них наиболее распространены (главным образом для калькулирования себестоимости единицы продукции) метод балльных оценок, агрегатный метод и метод корреляционных связей. Параметрические методы позволяют дать приближенную, но достаточно обоснованную оценку себестоимости, когда использование других методов невозможно из-за ограниченности исходных данных (при прогнозировании, долгосрочном планировании, проектировании новой продукции, ценообразовании и др.). Важной особенностью этих методов является увязка размера затрат с потребительскими свойствами продукции. [c.239]
По эмпирически выведенной формуле значение показателя сложности для предприятий органического синтеза определяется следующей зависимостью [c.58]
Параметрический метод используют лишь там, где возможно установить зависимость между производственными параметрами (техническими и др.) и затратами на производство. Такие зависимости можно установить на основе довольно трудоемких корреляционных методов с разработкой многочисленных эмпирических формул. Формулы эти недолговечны и по мере развития предприятия должны корректироваться, что не менее трудоемко, чем пересмотр норм. [c.170]
Массу новых средств устанавливают по-разному. В зависимости от стадии проектирования она может быть принята по чертежам, по эмпирическим формулам и номограммам, выражающим зависимость массы от тех или иных параметров средства на основании средних данных о массе аналогичных средств. [c.123]
Если новое оборудование однотипно с ранее освоенным, но отличается от него параметрами (производительностью, мощностью, скоростью и т. д.), то цена на него может быть установлена исходя из уровня цен на оборудование, составляющее с ним параметрический ряд. При этом методе оптовая цена на новое оборудование определяется по эмпирической формуле, характеризующей корреляционную зависимость цены на оборудование от основных его параметров. В первом приближении можно определить цену на новое оборудование в зависимости от одного параметра, например массы или производительности. При этом используются показатели цены аналогичного оборудования в расчете на единицу этого параметра. [c.140]
Тем самым игнорируются фундаментальные закономерности экономики качества, обоснованные теоретически и подтвержденные эмпирически наличие предела насыщения и экстремальный характер изменения эффекта потребления продукции вблизи него. Фактически это означает, что при увеличении К в любом интервале комплексный показатель качества Кк, определяемый по формулам (3.14), (3.24), также будет повышаться. Момент достижения наивысшей полезности продукции при определенном значении того или иного её свойства оказывается принципиально неуловимым. [c.80]
В литературе предложено значительное количество формул разной степени теоретической обоснованности и эмпирической подтверждаемое для выражения F(XJ). [10j, [1 1], [12]. Обобщая, например, опубликованные материалы по металлорежущим станкам, можно считать их самыми существенными свойствами следующие 1) производительность (II) срок службы (Т) ресурс двигателя (R) точность (А) уровень автоматизации А энерговооруженность (Э) к.п.д. энергетического воздействия на предмет труда (г ) массу (М). Интегральный показатель качества станка выражается формулой [c.125]
Упоминавшийся ранее морфологический метод может быть успешно применен и на данном этапе для упорядоченного представления альтернатив решения сформулированных инженерных задач по совершенствованию, рационализации (а иногда и устранению) каждой функции. Для этого строится классификационная таблица или морфологическая матрица. В левой её части приводятся все функции изделия, а в правой — потенциально возможные способы их осуществления. Каждому способу в соответствующей ячейке матрицы приписываются величины затрат и полезного эффекта, рассчитанные или по смете или по эмпирическим (а иногда теоретическим) формулам. Исследуются все потенциальные, т.е. конструктивные и технологически реализуемые сочетания способов выполнения функций. Общее их число может быть значительным. Оно равно NB = m» (N — число вариантов сочетания функций m — число анализируемых способов выполнения одной функции п — число выделенных функций. Например, при 5 функциях и 3-х вариантах выполнения каждой надо исследовать З5 = 243 сочетания). [c.136]
Формула (36) представляет собой степенной ряд. Обычно степенные ряды используются для аппроксимации зависимостей, аналитическое выражение которых неизвестно и которые заданы только эмпирическими значениями зависимой и независимой переменных. В данном же случае разложение в ряд получено теоретическим путем и имеет более глубокий смысл, чем простая подгонка проектных данных под определенную кривую, поскольку коэффициенты при его членах имеют вполне определенное экономическое содержание и размерность. [c.118]
Параметрический метод применим лишь там, где можно установить непосредственную связь между производственными (техническими и др.) параметрами и затратами на производство. Такие связи можно определить на основе довольно трудоемких корреляционных методов с установлением многочисленных эмпирических формул. Формулы эти не долговечны и с развитием техники, технологии и организации производств должны корректироваться, что не менее трудоемко, чем пересмотр норм. Поэтому параметрический метод, так же как и нормативный, не находит пока широкого применения. Методы расчета затрат на производство по факторам требуют значительно меньшего объема информации и в то же время обеспечивают удовлетворительную точность результатов, позволяют судить о роли различных направлений и факторов, влияющих на уровень расходов. [c.324]
Если для исходного ряда (1) удается подобрать подходящую функцию времени (эмпирическую формулу), прогноз по методу математической экстраполяции заключается в вычислении ее значений в будущие моменты времени. Экстраполяции по эмпирическим формулам возможны так же, как и в предыдущих случаях, в предположении неизменности в будущем чего-то, в данном случае неизменности найденной структуры формулы и значений коэффициентов, входящих в формулу. [c.220]
Экстраполяции по функциям времени нашли широкое распространение в экономическом прогнозировании. Объясняется это тем, что, как правило, при подборе эмпирических формул для представления наблюдаемого ряда не только придерживаются тех данных, которые существуют в виде исходного ряда (1), но привлекают и различные вспомогательные сведения об экономической сущности явления, факторах и причинах, его обусловивших. Правда, подобная информация учитывается лишь косвенно (например, в словесных ограничениях по поводу общего поведения кривой тренда за пределами интервала наблюдения), но она позволяет ближе подойти к реальной оценке развития процесса. [c.221]
На втором этапе в зависимости от конкретных целей дальнейшего использования аналитической формулы в задачу подбора вводят дополнительные ограничения. Обычно это ограничения по степени приближения (аппроксимации), виду эмпирической функции, поведению ее графика вне заданного интервала наблюдения. [c.222]
Этап 1. Сравнивая полученный график с кривыми различных эмпирических функций из математических справочников, определяем наиболее подходящие формулы, описывающие исходные данные [c.222]
Решение этой системы дает а0 = 1,98 а, = 0,84 аг = — 0,72. Значит, окончательная эмпирическая формула для расчета теоретических уровней имеет вид [c.224]
Перечислите основные этапы подбора эмпирических формул для ряда динамики. [c.243]
На первом этапе строят график исходного динамического ряда и путем сравнения его с графиком известных функций отбирают наиболее подходящие. При хорошем знании природы и характера изменения уровней рассматриваемого ряда подбор эмпирических формул производится непосредственно, без построения графиков. [c.201]
Корреляционная зависимость между производительностью труда и товарооборотом может измеряться, следовательно, по любой из приведенных формул. Однако логарифмическая форма связи в большей мере сближает теоретические значения средней выработки с эмпирическими. [c.305]
Коэффициенты целевой функции И7 т И7, g, , И7, д2 вычисляются на основании формул (137) — (149)